Using Karpathy’s Autoresearch to Identify Older Songs that could go TikTok Viral

Andrej Karpathy — former head of AI at Tesla and OpenAI founding member — released autoresearch in March 2026. The premise: if you have a goal and an approach, you can get an AI agent to loop through variations of that approach, testing what works and discarding what doesn’t, while you sleep.
How it works
You give the agent a training script (the approach), a dataset, and a single number that tells it whether things got better or worse (the goal). The agent modifies the script — changes the model architecture, adjusts parameters, tries a different optimisation technique — runs it, checks the score, keeps the change if it improved, reverts if it didn’t, and moves on. Each experiment runs for a fixed five minutes so every variation is compared fairly. A human researcher might get through five to ten of these iterations in a day. The agent runs a hundred overnight.
You can plug it in early when you’re still exploring, or hand it a model you’ve already spent weeks on and let it suggest improvements you might not have considered. Either way, the output is the same: a log of what it tried, what worked, and a better-performing model.
Karpathy built it to optimise a small language model. But the loop generalises to anything you can score — fraud detection, medical imaging, recommendation engines, or something less obvious.
We wanted to test it on a problem with extreme class imbalance, messy real-world data, and a question people might find interesting.
The TikTok time machine
Old songs keep resurfacing in the streaming era. Kate Bush’s “Running Up That Hill” (1985) went from relative obscurity to over 100 million Spotify streams after featuring in Stranger Things. Fleetwood Mac’s “Dreams” (1977) spiked after a skateboard TikTok. Boney M’s “Rasputin” (1978) became a dance trend. These are pre-2000 tracks suddenly charting alongside current releases.
We wanted to know whether these songs had anything in common — whether there’s a measurable audio profile that separates the songs that resurge from the millions that don’t. And if that profile exists, could we use it to flag which old songs might be next?
The goal was a model that takes a pre-2000 song’s audio features and outputs a resurgence probability between 0 and 1. The metric we chose was AUC-ROC — area under the receiver operating characteristic curve. In plain terms: if you randomly pick one song that did resurge and one that didn’t, AUC-ROC measures how often the model correctly ranks the resurged one higher. A score of 0.5 is random guessing. Anything above 0.8 generally means the model is finding signal. This metric is particularly suited to imbalanced problems where accuracy is misleading — a model that just says “no” to everything would be 99.97% accurate on our dataset but completely useless.
Building the dataset
We started with a massive Spotify catalogue — over 3.2 million pre-2000 tracks with full audio features: danceability, energy, valence (how happy a song sounds), tempo, loudness, acousticness, instrumentalness, and more. These features are computed by Spotify’s audio analysis pipeline and give us a numerical fingerprint for every song.
For labels, we needed to know which of these old songs had actually experienced a modern resurgence. We cross-referenced the catalogue against Spotify’s Global Top 200 weekly charts from 2017 to 2021. Any pre-2000 song that appeared on those charts got labelled as “resurged.” Everything else got labelled as “didn’t resurge.”
The result: 97 positive examples out of 3.2 million songs. A class ratio of 0.003%. This is extreme imbalance — the kind of dataset that breaks most models. We verified our labels against known resurgences: all 12 of our sanity-check songs (Fleetwood Mac, Kate Bush, Bee Gees, Queen, a-ha, and others) were correctly identified.
To make the dataset tractable for rapid experimentation, we filtered to artists with five or more tracks (removing obscure one-offs), dropped songs under one minute or over seven minutes (skits and extended jams), and downsampled the negatives to 100,000 while keeping all 97 positives. This gave us a 100k-row dataset with a 0.1% positive rate — still severely imbalanced, but small enough for the agent to train hundreds of models overnight.
In a pure autoresearch setup, you’d typically be iterating only on the neural network architecture and its hyperparameters within a fixed training framework. Our approach was a bit looser — we let the agent explore not just neural network configurations but also alternative model families and data augmentation strategies. This meant fewer total experiments than a tightly scoped autoresearch run, but a wider search space.
The overnight experiment
We spun up an A100 GPU on RunPod, uploaded the dataset, pointed Claude Code at our research instructions, and went to sleep.
The agent ran 28 experiments over the course of the session. Here’s what happened.
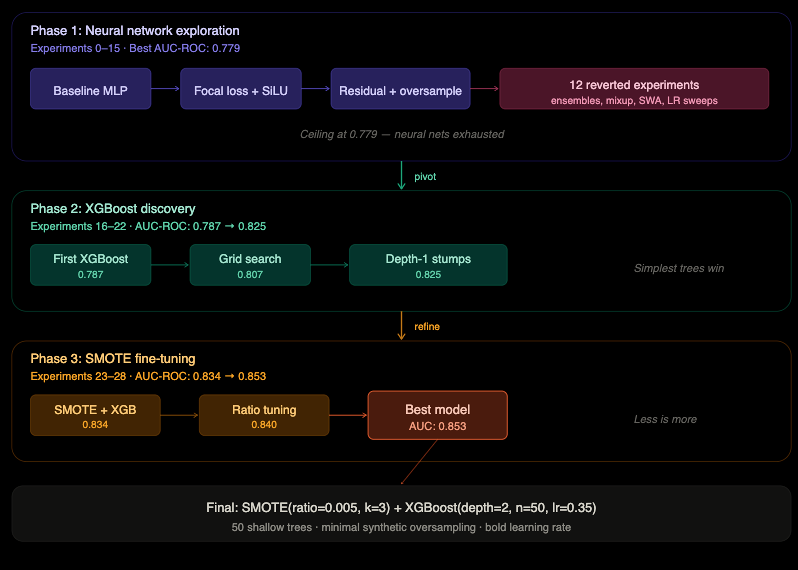
Phase 1: The neural network grind (Experiments 0–15). The agent started with a baseline multi-layer perceptron and methodically explored every neural network trick in the book. Focal loss for class imbalance. Residual connections. Ensemble models. Mixup data augmentation. Stochastic weight averaging. Learning rate sweeps. Fifteen experiments. The best result: 0.779 AUC-ROC. A ceiling the agent couldn’t break through.
Phase 2: The pivot (Experiments 16–22). On experiment 16, the agent abandoned neural networks entirely and tried XGBoost — a gradient-boosted tree model. Immediate jump to 0.787. It then discovered that the simplest possible trees (depth 1 — literally a single split per tree) with an aggressive learning rate outperformed every complex architecture it had tried. By experiment 19, it hit 0.825.
Phase 3: The refinement (Experiments 23–28). The agent discovered that SMOTE — a technique for generating synthetic positive examples — combined with XGBoost pushed performance further. But the key insight was less is more: only 0.5% synthetic oversampling, only 3 nearest neighbours for interpolation, only 50 trees. Every time it tried to go bigger, performance dropped.
Final result: 0.853 AUC-ROC. Meaning if you pick a random resurged song and a random non-resurged song, the model correctly ranks the resurged one higher 85.3% of the time.
The winning model is absurdly simple: 50 shallow decision trees, each making one or two splits, trained on a barely augmented dataset. It outperformed every sophisticated neural network the agent tried.
What the model learned
The feature importance analysis revealed a clear viral formula for old songs.
The strongest signal is instrumentalness — or rather, the lack of it. Songs that go viral have vocals. Instrumental tracks almost never resurge. Resurged songs average 0.014 instrumentalness versus 0.195 for the rest — a 14x difference. If your song doesn’t have a voice on it, the model says it’s not going anywhere.
Loudness matters. Louder songs resurge. They cut through on phone speakers, in car aux cables, and in TikTok videos where audio competes with everything else on the feed.
Decade matters, but not the way you’d expect. The 70s and 80s are the nostalgia sweet spot. 90s songs are less likely to resurge — perhaps because they haven’t been dormant long enough to feel like a rediscovery. Hollywood seems to agree: Project Hail Mary, currently the number one film in the world, leans heavily on a 70s soundtrack — Neil Diamond’s “Stargazer,” Miriam Makeba’s “Pata Pata,” Ike & Tina Turner’s “Glory, Glory.” The model and the music supervisors appear to be looking at the same era.
Valence — how happy a song sounds — is a strong predictor. Resurged songs average 0.611 valence versus 0.511 for the rest. People share music that feels good.
The interaction of energy and danceability matters more than either alone. You need both — energetic AND danceable. This is, essentially, the TikTok choreography signal. A slow ballad that’s energetic but not danceable doesn’t cut it. A danceable track that’s low energy doesn’t either. The combination is what drives a 15-second clip.
Less acoustic is better. Produced, polished recordings win over raw acoustic performances.
Major key songs resurge more than minor key. Happy keys for happy vibes.
And what doesn’t matter? Tempo has nearly zero correlation with resurgence. Duration has zero. Key signature has almost none. The model doesn’t care how fast the song is or how long it is. It cares whether it’s vocal, loud, happy, danceable, and energetic.
The formula, distilled: loud, happy, danceable, with vocals. Instrumentals and acoustic tracks need not apply.
The predictions
A model that scores songs is useful. A model that scores songs you’ve actually heard of is more useful. So we took the scored catalogue and matched it against the full Billboard Hot 100 historical chart data — every song that ever charted in the US from 1958 onwards. This let us filter for songs that were genuine hits in their era (top 40 on Billboard) but haven’t experienced a streaming resurgence. Out of 3.2 million songs scored, 465 dormant former hits survived the filter.
Five songs we’d watch. If we had to pick the tracks most likely to be the next “Dreams” or “Running Up That Hill” — former chart hits, currently dormant, with the right audio profile — these are them:
Gloria Gaynor’s “I Will Survive” (1978, Billboard #1). The model scores it high on every dimension that matters: danceable, vocal, loud, positive. It’s a song everyone knows but nobody is actively streaming. One sync or one TikTok trend and it’s back.
Carl Douglas’ “Kung Fu Fighting” (1974, Billboard #1). Eighteen weeks on the chart in its day. Danceable, high energy, distinctive hook. Meme-ready in a way that most 70s tracks aren’t.
The Human League’s “Don’t You Want Me” (1981, Billboard #1). A synth-pop track with the exact production profile the model favours — loud, polished, major key, strong vocal.
Del Shannon’s “Runaway” (1961, Billboard #1). Twenty-one weeks on the chart. The oldest song in our top predictions, which makes it interesting.
Irene Cara’s “Fame” (1980, Billboard #4). Twenty-six weeks on the chart. Energetic, danceable, vocal — and attached to an iconic film.
The deep cuts. For the cooler kids who don’t want the obvious picks, the model also surfaces songs that weren’t necessarily chart-toppers but have the right profile for rediscovery. Bill Withers’ “Lovely Day,” Harold Melvin & the Blue Notes’ “Don’t Leave Me This Way” (the Communards version scores even higher), Wilson Pickett’s “In the Midnight Hour” — soul and funk tracks with grooves that producers and DJs have been quietly sampling for decades. The model thinks the mainstream is about to catch up.
The Doors keep showing up. The model has a clear affinity for The Doors’ catalogue — “People Are Strange,” “Love Her Madly,” and “Riders on the Storm” all score well. These aren’t their most famous tracks (that would be “Light My Fire”), but they share an audio profile the model reads as high-potential: vocal, energetic, distinctive production.
We also found geographic clusters in the high-scoring songs that go beyond the Western pop canon. Brazilian music from the 70s — Os Mutantes, Os Originais Do Samba, Ney Matogrosso — dominates the model’s predictions, sharing an audio profile that’s danceable, energetic, and warm. Japanese city pop surfaces too, led by Taeko Onuki’s “Tokai” (1977), from a genre already having its moment online. Eastern European pop from behind the Iron Curtain — Hungarian, Polish, Czech acts — shows up unexpectedly with the same danceable-melodic DNA. These scenes may represent the next wave of resurgences once the obvious Western catalogue is exhausted.
What this can’t tell you, and what it can
The model identifies songs with the right audio profile for resurgence. What it can’t predict is the trigger. “Running Up That Hill” didn’t resurge because of its audio features — it resurged because the Duffer Brothers put it in Stranger Things. “Dreams” resurged because one person on a skateboard happened to pick it for a video. The audio profile is a necessary condition, not a sufficient one.
There’s a deeper analysis to be done — incorporating cultural signals like social media mentions, sync licensing data, artist activity, film and TV placements — that would make these predictions more actionable. We may explore that in future work.
But predicting viral songs wasn't really the point. We wanted to understand how autoresearch behaves on a messy problem — how it explores, where it gets stuck, and what it converges on. What we observed: the agent exhausted one approach (neural networks), hit a ceiling, pivoted to a fundamentally different model family (gradient-boosted trees), and then refined aggressively within that family. It arrived at a configuration — shallow XGBoost stumps with minimal SMOTE — that is counterintuitively simple. The discovery that 50 single-split trees outperform deep neural networks on this dataset is the kind of finding that emerges naturally from broad exploration, which is what autoresearch is built for.
At SimplyfAI, we’re applying autoresearch patterns across several use cases now. The specific model matters less than the loop: define your metric, give the agent room to explore, and wake up to results.



