Part 5: Attention is all you need

Part 5 of an ongoing series on Modern AI History.
While OpenAI's heist was getting underway in Menlo Park, progress at everyone's favourite search engine never paused. The next big AI breakthrough would come from Google, exactly as you'd expect — just not from the department anyone would have put money on.
Google Translate
If you used Google Translate seriously in the early 2010s — whether (1) to check, at the height of Barca and Madrid, if the Spanish papers had your player in their sights, or (2) to decode a bit of culture from some attractive stranger you'd bonded with on a tropical vacation — the output was likely to leave you with some combination of confused, shocked, and heartbroken, in whatever order. Its ability to take a three-line paragraph and come back with two lines of broken English and one line of something that wasn't a language at all made it a popular punchline.

Progress came slowly at first, then all at once. In September 2016, Google swapped the engine for one built on neural networks. The Chinese-to-English version shipped first. By the following spring, a dozen more languages had been flipped over. Translate stopped being a joke and started being a tool. The team had every reason to take a breath.
Instead, eight of them wrote another paper.
Attention Is All You Need
In June 2017, the eight published a paper with that title. To understand what it claimed, you need to know how machines read language before it.

They read the way we do — one word after another, trying to hold the whole thing in their head as they went. The problem was memory. By the time they reached the end of a long sentence, the start had faded. So in 2014, researchers added a trick called attention, which let the model, at each step, look back across everything it had already read and decide which earlier words mattered most to the one it was working on now. Think of a translator pausing on a tricky word, scanning back through the sentence, and landing their finger on the two or three words that actually tell them what to do. That was attention — a spotlight the model could shine on its own history.
It worked, but attention was still a helper. The model still had to read the sentence in order before the spotlight could do its job.
The 2017 paper made a stranger claim. If the spotlight is what's actually doing the useful work, why keep the reader at all? Why not let every word in the sentence shine its spotlight on every other word, all at once, and skip the sequential reading entirely? Every word directly querying every other word — how much do you matter to me? — and building its understanding from the answers.
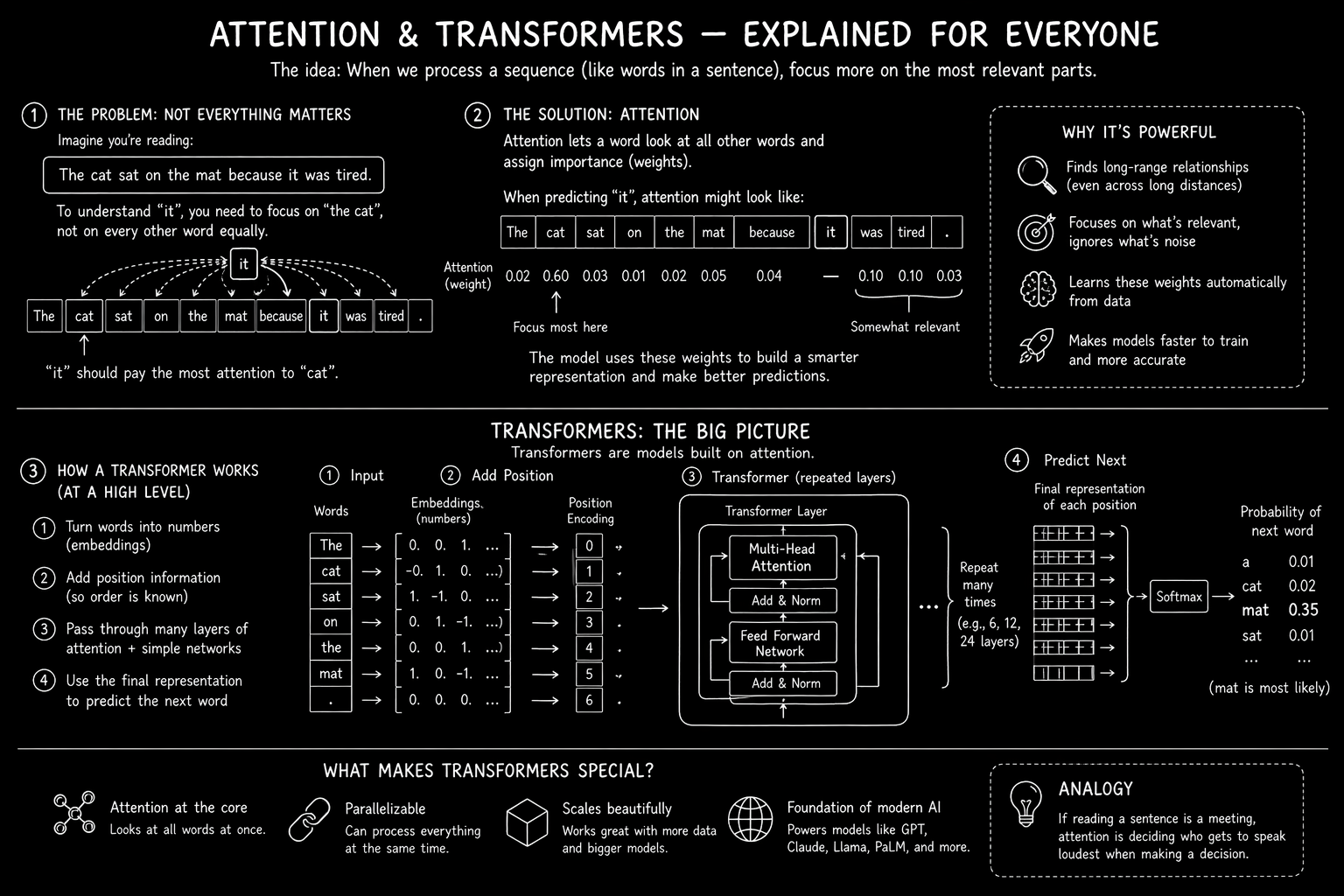
The streamlining had a huge payoff. Training got dramatically faster, which meant bigger models trained on more data. This architecture, with nothing but spotlights, is called the Transformer. It's the T in GPT.
A Quick Refresher
I'm going to buck the trend and do a quick stock take. A lot has happened. Nvidia's chips, originally built for video games, had given the field more computing power than it had ever had. CUDA let researchers use those chips for anything, including training neural networks — an old idea, loosely modelled on the brain, that until 2012 most of AI had written off. Breakthroughs like AlexNet, backed by the new compute, demonstrating huge improvements signal the turning point. Research on neural networks accelerated, and money followed it — first into the labs chasing deeper applications like AGI, then, as fears grew that Google would end up owning all of it, into the rivals set up to stop them. Competition brought in more cash, more talent, and more ambition. And then the Transformer — a streamlined take on the same neural network idea — arrived and gave all of it a faster, more powerful foundation to build on.
The Road to El Dorado
OpenAI, led by Ilya Sutskever, immediately saw what the Transformer was worth and bet the company on it. Between 2018 and 2020, they released three versions of the same idea — a system built to read and write human language well enough that you could talk to it like a person and get useful answers back. They called it GPT. GPT-1 was a proof of concept. GPT-2, a year later, wrote coherent paragraphs. GPT-3, in 2020, had a hundred and seventy-five billion parameters and could write essays, hold conversations, and generate working code.

We said every heist has a dining scene. The other thing it's bound to have is internal conflict, especially with the bounty in sight. While the models kept getting better, OpenAI was fighting to survive itself. Elon Musk, who had co-founded the company and bankrolled much of its early work, had grown increasingly frustrated with the pace. In early 2018, he told the board OpenAI was falling behind Google and pitched himself as the person to take it over and run it directly. The board, with Altman at the centre, turned him down. Musk walked, citing a conflict of interest with Tesla's own AI work, and took his chequebook with him. A year later, Altman restructured the company from a pure non-profit into a capped-profit entity to take a billion dollars from Microsoft, arguing it was the only way to afford the compute the scaling bet required.
In that watershed moment of November 2022, perhaps Sam Altman cracked that attention really was all you needed — albeit in a very different context to the Google Translate team. Before we get there, it wasn't just Elon who had fallen out with the direction. As the company changed, some of the purists grew unsettled. One of them, more than most, was Dario Amodei. Told you we'd get to him.
→ Next: Amodei, Anthropic & the Lesson of Paul Atreides
← Previous: Open's Eleven
Read the full series: Modern AI History


